


What is an Entity ?
An entity is s physical representation of a logical grouping of data. Entities can be tangible, real things, such as a PERSON or ICE CREAM, or intangible concepts, such as a COST CENTER or MARKET. Entities do not represent single things. Instead, they represent collections of instances that contain the information of interest for all instances or occurrences. For example a PERSON entity represents instances of things of type Person. Gabriel De Angelies, R.J golcher, Jessica Corter, and Venessa Westley are examples of specific instances of PERSON. A specific instance of an entity is represented by a row and is identified by a primary key.
An entity has the following characterstics:
• It has a name and description.
• It represents a class, rather than a single instance of a concept.
• It has the ability to uniquely identify each specific instance.
• It contains a logical grouping of attributes representing the information of
interest to the enterprise.
Formal Entity Definitions
The following list contains entity definitions from some of the most influential leaders in data modeling. Notice the similarities:
• Chen (1976): “A thing which can be distinctly identified.”
• Date (1986): “Any distinguishable object that is to be represented in the database.”
• Finklestein (1989): “A data entity represents some ‘thing’that is to be stored for later reference. The term entity to the logical representaion of data.”
Defining Entity Types
Within the independent and dependent entities are entity types:
• Core entities-- These are sometimes called primary or prime entities. They represent the important objects about which the enterprise in interested in keeping data.
• Code/reference/classification entities-These entities contain rows that define the set of values, or domain, for an attribute.
• Associative entities--These entities are used to resolve many-to-many relationships.
• Subtype entities-These entities come in two types, exclusive and inclusive.
Core Entity
Core entities are the most important objects about which an enterprise is interested in keeping data. They are often referred to as prime, principal, or primary entities. Because these entities are so important, it is likely that they are used elsewhere in the enterprise. Take the time to look for similar entities because there are many opportunities for the reuse of core entities. Core entities should be modeled consistently throughout the enterprise. Good modelers consider this an essential best practice.

Note the straight corners of the independent entities, STORE and ICE CREAM and the rounded corners of the dependent entity STORE ICE CREAM.
A core entity can be an independent entity or a depenent entity. Figure 2.1 provides examples of core entities for an enterprie that sells ice cream. ICE CREAM represents the base products sold by the enterprise. STORE is an example of a distribution channel, or the vehicle through which a product is sold.
Consider that the enterprise is doing well and has decided to add another STORE. The model requires no change to support the addittion of a new instance of STORE. It is simpy another row added to the STORE entity. The same applies to ICE CREAM.
Notice the core entities ICE CREAM and STORE. Although the example may seem straight forward, it illustrates a powerful concept regarding the modeling of core entities.
Understanding how to model core entities as scalable and extensible containers of information requires the modeler to think about the entity as an abstract concept and to model the information independently of the way it is used today. In this example, model ICE CREAM completely outside the context of STORE and vice versa. So, if the enterprise decides to sell ICE CREAM using an addittional channel, such as the Internet or door-to-door, the new channel can be added without distrubing other entities.
Code Entity
Code entities are always independent entities. They are often referred to as reference, classification, or type entities, depending on the methodology. The unique instances represented by code entities define the domain of values for attributes present in other entities. You might be tempted to use a single attribute in a code table. It is a best practice to include at least three attributes in a code entity: an identifier, a name (sometimes called a short name), and a description.
In Figure 2.2, TOPPING is an independent entity; note the sharp corners. TOPPING is also a code or classification entity. The instances (or rows) of TOPPING define the list of toppings available.

Figure 2.2
Code entities allow an enterprise to define a set of values for consistent use throughoput the enterprise. The instances of a code entity define a domain of values for use elsewhere in the model.
Code entities usually contain a limited number of attributes. I have seen instances where these entities contain only a single attribute. I prefer to model code entities with an artificial identifier. Using an artificial identifier, along with a name and description, allows the addittion of new kinds of TOPPING to be added as instances (rows) in the entity. Note that TOPPING contains three attributes.
I often refer to code entities as corporate business objects. The name, corporate business objects, indicates that the entities are defined and shared at a corporate level, not by a single application, system, or business unit. These entities are often shared by many databases to allow consistent roll-up reporting or trending analysis.
Associative entity
Associative entities are entities that contain the primary key from two or more other entities. Associative entities are always dependent entities. They are used to resolve many-to many relationships between other entities. Many – to many relationships are those in which many instances of one entity are related to many instances of another. Associative entities allow us to model the intersection between the instances of the two entities, thereby allowing each instance in the associatie entity to be unique.
Note
Many- to – many relationships cannot be implemented in a physical database. ERwin will automatically create an associative entity to resolve a many-tomany relationship when the model is changed from logical to physical mode.
Figure 2.1 uses an associative entity to resolve a many-to-many relationship between STORE and ICE CREAM. The addittion of an associative entity allows the same ICE CREAM to be sold in many instances of STORE, while not requiring every STORE to sell the same ICE CREAM. The associative entity STORE ICE CREAM resolves the fact that an instance of STORE sells many instances of ICE CREAM and an instance of ICE CREAM is sold by many instances of STORE.
Subtype Entity
Subtype entities are always dependent entities. You should use subtype entities when it makes sense to keep different sets of attributes for the instances of an entity. Finklestein refers to subtype entities as secondary entities. Subtype entities almost always have one or more “sibling” entities. The subtype entity siblings are related to a parent entity through a special relationship that is either exclusive or inclusive.
Note
Subtype sibling entities that have an exclusive relationship to the parent entity indicate that only one sibling has an instance for each instance of the parent entity. Exclusive subtypes represent an “is a” relationship.
Subtype sibling entities that have an inclusive relationship to the parent entity indicate that more than one sibling can have an instance for each instance of the parent entity.
Figure 2.3 shows the CONTAINER entity and the subtype entities CONE and CUP. The ice cream store apparently does not sell ice cream in bulk, only single servings. Note that an instance of CONTAINER must be either a CONE or a CUP. A CONTAINER cannot be both a CONE and a CUP. This is an exclusive subtype.
Figure 2.3, the PERSON entity has two subtypes, EMPLOYEE and CUSTOMER. Note that an exclusive subtype would not allow a single instance of PERSON to contain facts common to both an EMPLOYEE and a CUSTOMER. A VENDOR can also be a CUSTOMER.These are examples of inclusive subtypes.
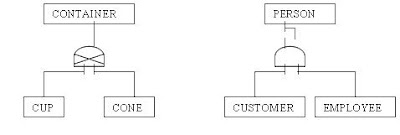
Figure2.3
Two examples of subtype entities, PERSON and CONTAINER. Both use ERwin IE notation to represent exclusive and inclusive subtypes. The (X) in the subtype symbol of CONTAINER indicates exlusive. The absence of the (X) in the subtype symbol indicates inclusive.
Structure Entity
Sometimes, instances of the same entity are related. In his 1992 book Strategic Systems Development, Clive Finklestein proposes the use of a structure entity to represent relationships between instances of an entity. Relationships between instances of an entity are called recursive relationships. “ Recursive relationships are a logical concept, a concept sometimes difficult for users to grasp.
Figure 2.4 shows the addittion of a structure entity that allows a relationship between instances of EMPLOYEE. The diagram shows that the EMPLOYEE subtype of the PERSON entity has two subtypes, SERVER and MANAGER. The EMPLOYEE STRUCTURE entity represents the relationship between instances of EMPLOYEE.
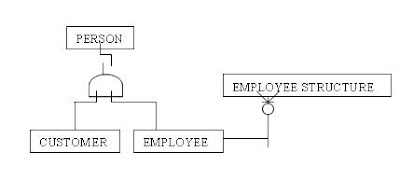
Figure 2.4
Structure entity illustrates Clive Finklestein’s resolution for recursive relationship.
Naming Entities
The name assigned to an entity should be indicative of the instances of the entity. The name should be understood and accepted across the enterprise. When selecting a name, keep an enterprise view and take care to use a name that reflects how the data is used throughout the entire enterprise, not just a single area. Use names that are meaningful to the user community and domain experts.
I hope you have a set of naming conventions that were developed for use in the enterprise, or an enterprise data model, to guide you. Using naming conventions ensures that names are constructed consistently across the enterprise, regardless of who constructs the name. The following sections provide a starter set of naming conventions and give examples of good and bad names.
Entity Naming Conventions
Naming conventions might not seem important if you work in a small organization with a small set of users. However, in a large organization with many development teams and many users, naming conventions greatly facilitate communication and data sharing. As a best practice, you should develop and maintain naming conventions in a central location and then document and publish them for the whole enterprise.
I include some pointers for beginning a good set of naming conventions, just in case your organization has not yet developed one:
• An entity name should be as descriptive as necessary. Use single-word names only when the name is a widely accepted concept. Consider using noun phrases.
• An entity name should be a singular noun or noun phrase. Use PERSON instead of PERSONS or PEOPLE, or CONTAINER instead of CONTAINERS.
• An entity name should be unique. Using the same entity name to contain different data, or a different entity name to contain the same data, is needlessly confusing to developers and users alike.
• An entity name should be indicative of the data that will be contained for each instance.
• An entity name should be indicative of the data that will be contained for each instance.
• An entity name should not contain special characters (such as! @,#,$,%,^,&,*, and so on) or show possession (PERSON’S ICE CREAM).
• An entity name should not include acronyms or abbreviations unless they are part of the accepted naming conventions.
I encourage modelers to use good naming conventions if they are available and to develop them if they do not follow these guidelines.
An entity is s physical representation of a logical grouping of data. Entities can be tangible, real things, such as a PERSON or ICE CREAM, or intangible concepts, such as a COST CENTER or MARKET. Entities do not represent single things. Instead, they represent collections of instances that contain the information of interest for all instances or occurrences. For example a PERSON entity represents instances of things of type Person. Gabriel De Angelies, R.J golcher, Jessica Corter, and Venessa Westley are examples of specific instances of PERSON. A specific instance of an entity is represented by a row and is identified by a primary key.
An entity has the following characterstics:
• It has a name and description.
• It represents a class, rather than a single instance of a concept.
• It has the ability to uniquely identify each specific instance.
• It contains a logical grouping of attributes representing the information of
interest to the enterprise.
Formal Entity Definitions
The following list contains entity definitions from some of the most influential leaders in data modeling. Notice the similarities:
• Chen (1976): “A thing which can be distinctly identified.”
• Date (1986): “Any distinguishable object that is to be represented in the database.”
• Finklestein (1989): “A data entity represents some ‘thing’that is to be stored for later reference. The term entity to the logical representaion of data.”
Defining Entity Types
Within the independent and dependent entities are entity types:
• Core entities-- These are sometimes called primary or prime entities. They represent the important objects about which the enterprise in interested in keeping data.
• Code/reference/classification entities-These entities contain rows that define the set of values, or domain, for an attribute.
• Associative entities--These entities are used to resolve many-to-many relationships.
• Subtype entities-These entities come in two types, exclusive and inclusive.
Core Entity
Core entities are the most important objects about which an enterprise is interested in keeping data. They are often referred to as prime, principal, or primary entities. Because these entities are so important, it is likely that they are used elsewhere in the enterprise. Take the time to look for similar entities because there are many opportunities for the reuse of core entities. Core entities should be modeled consistently throughout the enterprise. Good modelers consider this an essential best practice.

Note the straight corners of the independent entities, STORE and ICE CREAM and the rounded corners of the dependent entity STORE ICE CREAM.
A core entity can be an independent entity or a depenent entity. Figure 2.1 provides examples of core entities for an enterprie that sells ice cream. ICE CREAM represents the base products sold by the enterprise. STORE is an example of a distribution channel, or the vehicle through which a product is sold.
Consider that the enterprise is doing well and has decided to add another STORE. The model requires no change to support the addittion of a new instance of STORE. It is simpy another row added to the STORE entity. The same applies to ICE CREAM.
Notice the core entities ICE CREAM and STORE. Although the example may seem straight forward, it illustrates a powerful concept regarding the modeling of core entities.
Understanding how to model core entities as scalable and extensible containers of information requires the modeler to think about the entity as an abstract concept and to model the information independently of the way it is used today. In this example, model ICE CREAM completely outside the context of STORE and vice versa. So, if the enterprise decides to sell ICE CREAM using an addittional channel, such as the Internet or door-to-door, the new channel can be added without distrubing other entities.
Code Entity
Code entities are always independent entities. They are often referred to as reference, classification, or type entities, depending on the methodology. The unique instances represented by code entities define the domain of values for attributes present in other entities. You might be tempted to use a single attribute in a code table. It is a best practice to include at least three attributes in a code entity: an identifier, a name (sometimes called a short name), and a description.
In Figure 2.2, TOPPING is an independent entity; note the sharp corners. TOPPING is also a code or classification entity. The instances (or rows) of TOPPING define the list of toppings available.

Figure 2.2
Code entities allow an enterprise to define a set of values for consistent use throughoput the enterprise. The instances of a code entity define a domain of values for use elsewhere in the model.
Code entities usually contain a limited number of attributes. I have seen instances where these entities contain only a single attribute. I prefer to model code entities with an artificial identifier. Using an artificial identifier, along with a name and description, allows the addittion of new kinds of TOPPING to be added as instances (rows) in the entity. Note that TOPPING contains three attributes.
I often refer to code entities as corporate business objects. The name, corporate business objects, indicates that the entities are defined and shared at a corporate level, not by a single application, system, or business unit. These entities are often shared by many databases to allow consistent roll-up reporting or trending analysis.
Associative entity
Associative entities are entities that contain the primary key from two or more other entities. Associative entities are always dependent entities. They are used to resolve many-to many relationships between other entities. Many – to many relationships are those in which many instances of one entity are related to many instances of another. Associative entities allow us to model the intersection between the instances of the two entities, thereby allowing each instance in the associatie entity to be unique.
Note
Many- to – many relationships cannot be implemented in a physical database. ERwin will automatically create an associative entity to resolve a many-tomany relationship when the model is changed from logical to physical mode.
Figure 2.1 uses an associative entity to resolve a many-to-many relationship between STORE and ICE CREAM. The addittion of an associative entity allows the same ICE CREAM to be sold in many instances of STORE, while not requiring every STORE to sell the same ICE CREAM. The associative entity STORE ICE CREAM resolves the fact that an instance of STORE sells many instances of ICE CREAM and an instance of ICE CREAM is sold by many instances of STORE.
Subtype Entity
Subtype entities are always dependent entities. You should use subtype entities when it makes sense to keep different sets of attributes for the instances of an entity. Finklestein refers to subtype entities as secondary entities. Subtype entities almost always have one or more “sibling” entities. The subtype entity siblings are related to a parent entity through a special relationship that is either exclusive or inclusive.
Note
Subtype sibling entities that have an exclusive relationship to the parent entity indicate that only one sibling has an instance for each instance of the parent entity. Exclusive subtypes represent an “is a” relationship.
Subtype sibling entities that have an inclusive relationship to the parent entity indicate that more than one sibling can have an instance for each instance of the parent entity.
Figure 2.3 shows the CONTAINER entity and the subtype entities CONE and CUP. The ice cream store apparently does not sell ice cream in bulk, only single servings. Note that an instance of CONTAINER must be either a CONE or a CUP. A CONTAINER cannot be both a CONE and a CUP. This is an exclusive subtype.
Figure 2.3, the PERSON entity has two subtypes, EMPLOYEE and CUSTOMER. Note that an exclusive subtype would not allow a single instance of PERSON to contain facts common to both an EMPLOYEE and a CUSTOMER. A VENDOR can also be a CUSTOMER.These are examples of inclusive subtypes.

Figure2.3
Two examples of subtype entities, PERSON and CONTAINER. Both use ERwin IE notation to represent exclusive and inclusive subtypes. The (X) in the subtype symbol of CONTAINER indicates exlusive. The absence of the (X) in the subtype symbol indicates inclusive.
Structure Entity
Sometimes, instances of the same entity are related. In his 1992 book Strategic Systems Development, Clive Finklestein proposes the use of a structure entity to represent relationships between instances of an entity. Relationships between instances of an entity are called recursive relationships. “ Recursive relationships are a logical concept, a concept sometimes difficult for users to grasp.
Figure 2.4 shows the addittion of a structure entity that allows a relationship between instances of EMPLOYEE. The diagram shows that the EMPLOYEE subtype of the PERSON entity has two subtypes, SERVER and MANAGER. The EMPLOYEE STRUCTURE entity represents the relationship between instances of EMPLOYEE.

Figure 2.4
Structure entity illustrates Clive Finklestein’s resolution for recursive relationship.
Naming Entities
The name assigned to an entity should be indicative of the instances of the entity. The name should be understood and accepted across the enterprise. When selecting a name, keep an enterprise view and take care to use a name that reflects how the data is used throughout the entire enterprise, not just a single area. Use names that are meaningful to the user community and domain experts.
I hope you have a set of naming conventions that were developed for use in the enterprise, or an enterprise data model, to guide you. Using naming conventions ensures that names are constructed consistently across the enterprise, regardless of who constructs the name. The following sections provide a starter set of naming conventions and give examples of good and bad names.
Entity Naming Conventions
Naming conventions might not seem important if you work in a small organization with a small set of users. However, in a large organization with many development teams and many users, naming conventions greatly facilitate communication and data sharing. As a best practice, you should develop and maintain naming conventions in a central location and then document and publish them for the whole enterprise.
I include some pointers for beginning a good set of naming conventions, just in case your organization has not yet developed one:
• An entity name should be as descriptive as necessary. Use single-word names only when the name is a widely accepted concept. Consider using noun phrases.
• An entity name should be a singular noun or noun phrase. Use PERSON instead of PERSONS or PEOPLE, or CONTAINER instead of CONTAINERS.
• An entity name should be unique. Using the same entity name to contain different data, or a different entity name to contain the same data, is needlessly confusing to developers and users alike.
• An entity name should be indicative of the data that will be contained for each instance.
• An entity name should be indicative of the data that will be contained for each instance.
• An entity name should not contain special characters (such as! @,#,$,%,^,&,*, and so on) or show possession (PERSON’S ICE CREAM).
• An entity name should not include acronyms or abbreviations unless they are part of the accepted naming conventions.
I encourage modelers to use good naming conventions if they are available and to develop them if they do not follow these guidelines.






